저번 세션에서 tesseract를 사용해 OCR을 실습해봤는데요, 영어 텍스트는 아주 잘 인식하는 반면 한글 텍스트는 한글 트레인 데이터를 추가해줬음에도 형편 없는 성능을 보였습니다. 그래서 한글 텍스트 인식에 효과적이라는 clova api를 사용해볼지 말지 생각해보고 하든 말든 하겠다고 했는데요, 했습니다. 결론적으로 성능은 아주 훌륭했고, 단계별로 차례차례 정리해놓았으니 따라하시기 어렵지 않을 겁니다.
여전히 늘 ocr 실습을 하던 가상환경 ocr_projects에서 진행했습니다.

네이버 clova api 서비스를 사용하기 위해선 먼저 naver cloud platform에 가입해야해요. 아래 링크로 접속해 ocr 서비스에 대해 이용신청 버튼을 누르면 회원가입하거나 로그인하는 창으로 안내됩니다. 회원가입을 진행해주세요.
https://www.ncloud.com/product/aiService/ocr
NAVER CLOUD PLATFORM
cloud computing services for corporations, IaaS, PaaS, SaaS, with Global region and Security Technology Certification
www.ncloud.com

회원가입을 완료하면 2번 검은색 박스의 '콘솔로 이동' 버튼을 클릭해 콘솔로 이동합니다.

콘솔로 이동하면 이런 화면이 보일 거예요. 여기까지 하면 이제 clova가 제공하는 서비스에 대해 이용 신청을 할 준비를 마친 겁니다.

API 서비스를 이용하기 위해 먼저 API Gateway라는 서비스에 대해 이용신청을 해줍니다. 나중에 API gateway 자동연결을 위해 필요해요.
왼쪽 메뉴바에서 Services를 클릭한 후 나타나는 검색창에 원하는 서비스명을 검색하고 해당 서비스가 뜨면 클릭해주세요.

그 후, 드디어 Clova OCR 서비스를 이용할 단계에요. 마찬가지로 Services 탭에서 ocr을 검색하면 clova ocr에 접속할 수 있어요.
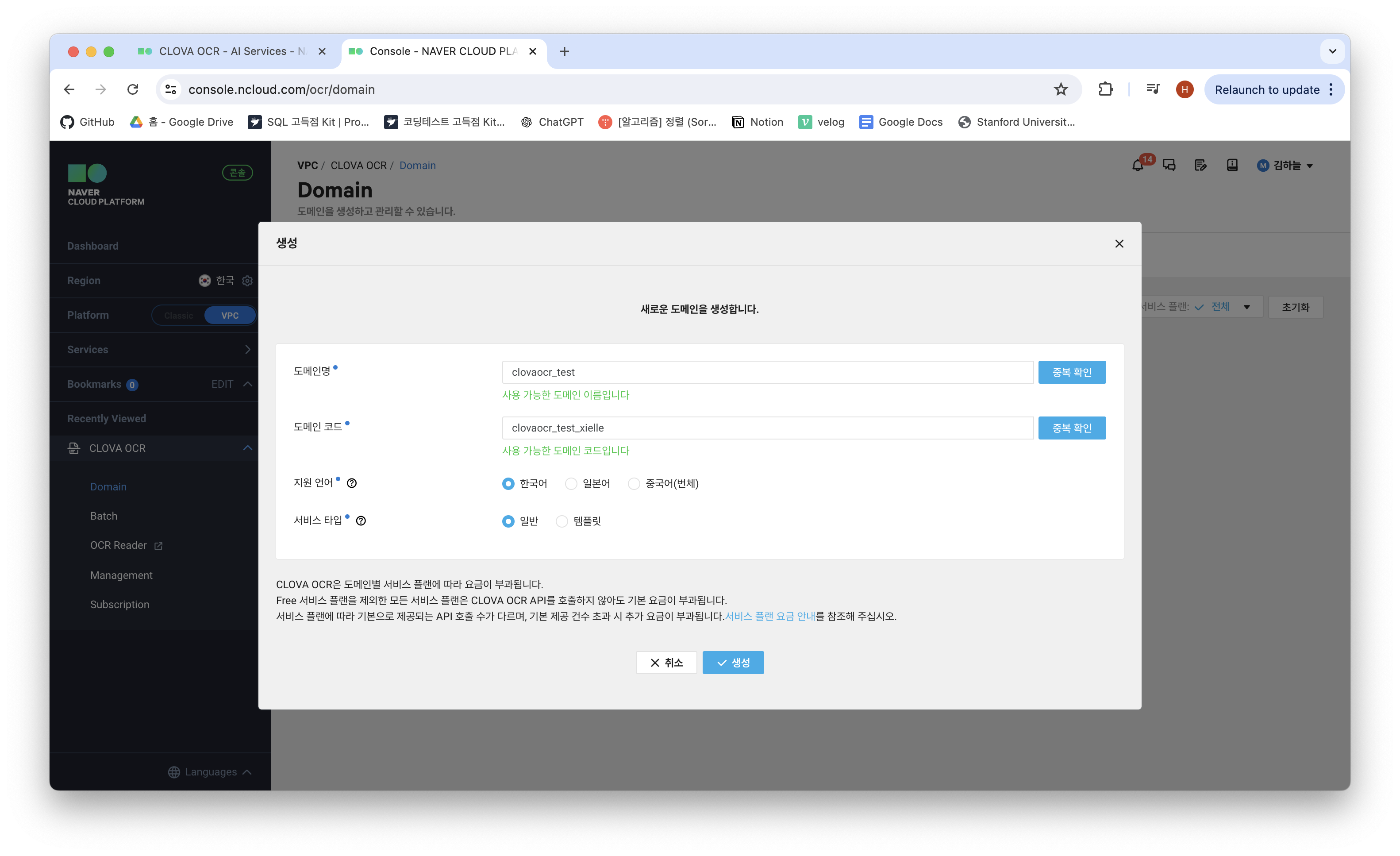
'도메인 생성하기' 버튼을 클릭합니다.
도메인명과 도메인 코드를 설정해주세요. 서비스 타입은 꼭 '일반'으로 하셔야 합니다. 템플릿으로 하는 경우 요금이 발생할 수 있어요. (일반도 많이 하면 발생하긴 하는데 이 정도 실습에선 그렇게 많이 api 호출할 일이 없습니다. 걱정 마세요.)

도메인 생성이 성공적으로 완료되었으면, 화면처럼 방금 생성한 도메인이 목록에 보일 거예요. 여기에서, 옵션 열에 있는 'API Gateway 연동' 버튼을 눌러주세요.

API Gateway 자동 연동을 해주면, 화면처럼 Secret Key와 APIGW Invoke URL이 생성된 걸 확인할 수 있습니다. 이 두 가지 키를 나중에 사용할 거예요.
이제 naver cloud platform에서 할 일은 모두 마쳤습니다. vscode로 돌아가 코드를 작성할 일만 남았어요.

코드를 작성하기 전에, 필요한 패키지를 가상환경 상에 다운로드 받아 줄게요. 터미널을 열고, 가상환경을 활성화한 후, pip install requests 명령어를 통해 requests를 설치합니다. api 요청을 보낼 때 사용할 거예요.

vscode에서 새로운 파이썬 파일을 생성합니다.

텍스트 인식에 입력할 이미지는 저번 세션에서 사용한 것과 동일한 지류 영수증 스캔 이미지입니다.

전체 코드입니다. 이제부터 하나하나 어떤 역할을 하는지 살펴볼게요.
import libraries

필요한 라이브러리들을 import하는 부분입니다.
각 라이브러리는 다음과 같은 역할을 합니다.
- json
: JSON 직렬화 및 역직렬화를 위한 라이브러리 - requests
: HTTP 요청을 보내기 위한 라이브러리 - uuid
: 고유 식별자를 생성하기 위한 라이브러리 - time
: 시간 관련 기능을 위한 라이브러리
API Credentials and URL

API 요청을 인증하기 위한 비밀키와 api gateway의 url 엔드포인트를 설정해줍니다. 바로 이 부분에 아까 도메인을 연결하고 얻은 값들을 넣어줍니다.
prepare images

모델에 입력할 이미지를 준비합니다. 이미지파일의 경로를 명시하고, 바이너리 읽기모드로 열어 튜플 형태로 준비합니다.
create request json

API에 보낼 JSON 요청 본문을 생성합니다. json 요청의 구조를 살펴보면 다음과 같습니다.
- images: 이미지 형식과 이름을 포함 (이 때 이름은 임의로 지어도 무관)
- requestId: UUID를 사용하여 고유한 요청 ID를 생성
- version: API 버전 명시
- timestamp: 현재 시간을 밀리초 단위로 표시
create payload & set headers

request_json을 JSON 문자열로 직렬화하고 UTF-8로 인코딩하여 API 요청에 사용할 페이로드를 생성합니다. 동시에, API 요청에 사용할 헤더를 설정하는데, 여기에서는 비밀키를 포함합니다.
API requests & response

requests.request를 사용하여 POST 요청을 보내고 response 변수에 응답을 저장합니다. 그런 다음, response.json을 이용해 응답을 JSON 형식으로 파싱하여 result 변수에 담습니다.
result에서 추출된 각 필드에 대해 각 필드에서 추출된 텍스트를 출력합니다.
results
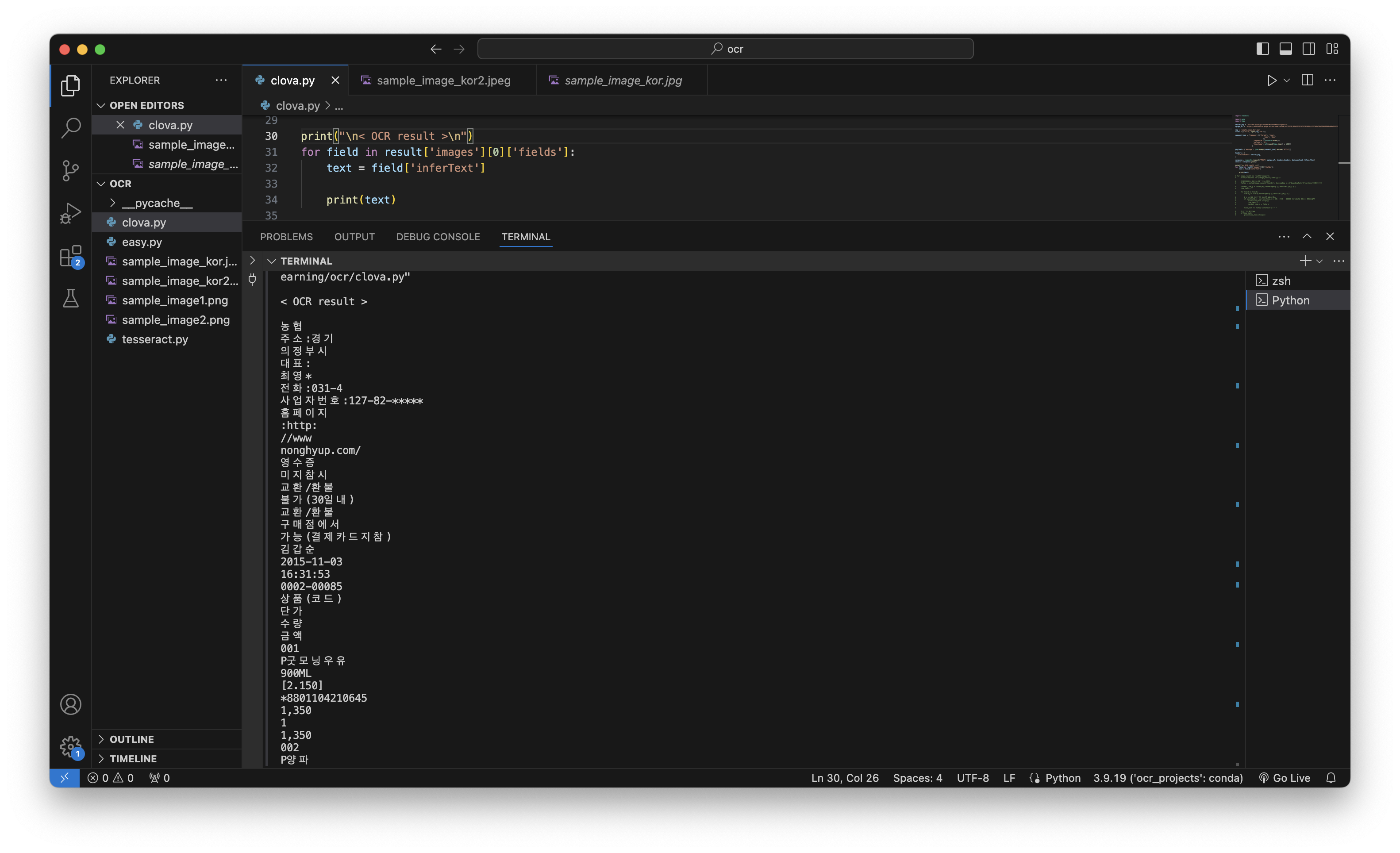
실행하면, 위와 같이 변환된 텍스트를 콘솔 창에서 확인할 수 있습니다. 여전히 아주 미세한 오류가 있지만, tesseract보다 눈에 띄게 나은 성능을 보여줍니다.
'Study > Deep Learning' 카테고리의 다른 글
| [OCR] #3_Python Practice Tesseract & OCR 파이썬 실습 (0) | 2024.08.02 |
|---|---|
| [OCR] #2_Improving OCR quality with Preprocessing OCR 성능향상을 위한 전처리 방법들 (0) | 2024.08.01 |
| [OCR] #1_OCR Intro OCR이란 (0) | 2024.08.01 |
| [Object Detection] #2_OpenCV & YOLOv8 & DeepSORT 객체탐지와 객체추적 (0) | 2024.08.01 |
| [Object Detection] #1_Object Detection Intro 객체탐지란 (0) | 2024.07.31 |